


同事查日志太慢,我现场教他一套 awk、tail、grep、sed 组合拳
作为后端开发者,熟练掌握 Linux 日志分析命令是我们的基本功。这些工具不仅能帮我们快速定位问题,还能避免像上面那样的尴尬局面。今天,我就来分享一套“组合拳”:基于 tail、less、grep、sed 和 awk 的日志查询技巧。这些都是我日常工作中常用的场景,能让你从日志海洋中高效捞针。无论你是新手还是老鸟,都值得收藏备用!
tail:实时监控日志的神器
很多新手喜欢用 cat 查看日志,但对于大文件来说,它会导致屏幕刷屏,甚至卡死终端。相比之下,tail 是实时监控的首选工具,能让你轻松跟踪日志的最新变化,而不干扰历史内容。
真实场景 A:服务发版启动监控
每次发版重启服务时,我们都需要确认 Spring Boot 是否启动成功,或者有没有初始化报错。
# -f (follow):实时追加显示文件尾部内容
tail -f logs/application.log
真实场景 B:配合测试复现 Bug
测试同学说:“我现在点一下按钮,你看看后台有没有报错。”此时,只需盯着最新的输出。
# 只看最后 200 行,并保持实时刷新,避免被历史日志干扰
tail -n 200 -f logs/application.log
额外提示:如果日志文件很大,结合 tail 和管道符(如 tail -f | grep "ERROR")可以进一步过滤,只显示关键信息,提高效率。
less:高效浏览大文件的利器
如果需要查看历史日志,less 是更好的选择。它不像 vim 那样一次性加载整个文件,而是按需加载,即使是几个 GB 的日志也能秒开。而且,它支持向前/向后搜索和实时模式切换。
真实场景:追查某笔客诉订单
运营反馈:刚才 10 点左右,订单号 ORD12345678 支付失败了。你需要从日志末尾开始,往前反向查找这个订单号。
less logs/application.log
进入界面后的操作流:
Shift + G:先跳到日志最末尾(因为报错通常发生在最近)。?ORD12345678:输入问号 + 订单号,向上反向搜索。n:如果当前这行不是关键信息,按 n 继续向上找上一次出现的位置。Shift + F:如果日志又更新了,按这个组合键进入类似tail -f的实时滚动模式;按Ctrl + C退回浏览模式。
额外提示:less 还支持标记行(用 m 键)和跳转(用 ' 键),非常适合长时间分析。相比 more,它更灵活。
grep:精准搜索的万能钥匙
grep 是最常用的搜索命令,但单纯的关键词搜索往往不够。在业务中,我们需要结合上下文、排除干扰或统计频次来挖掘信息。
真实场景 A:还原报错现场(重点)
只看到 NullPointerException 这一行往往无法定位问题,我们需要知道报错前的请求参数和后的堆栈信息。
# 搜索异常关键字,并显示该行 "前后各 20 行"
grep -C 20 "NullPointerException" logs/application.log
真实场景 B:全链路追踪 TraceId
微服务中,通过 TraceId 串联请求。日志可能滚动成了多个文件(如 app.log、app.log.1)。
# 搜索当前目录下所有以 app.log 开头的文件
grep "TraceId-20251219001" logs/app.log*
真实场景 C:统计异常频次
老板问:“Redis 超时异常今天到底发生了多少次?是偶发还是大规模?”
# -c (count):只统计匹配的行数
grep -c "RedisConnectionException" logs/application.log
真实场景 D:排除干扰噪音
日志里充斥无关的 INFO 心跳日志,干扰视线。
# -v (invert):显示不包含 "HealthCheck" 的所有行
grep -v "HealthCheck" logs/application.log
额外提示:结合正则表达式(如 grep -E "ERROR|WARN"),可以搜索多个模式,进一步提升搜索精度。

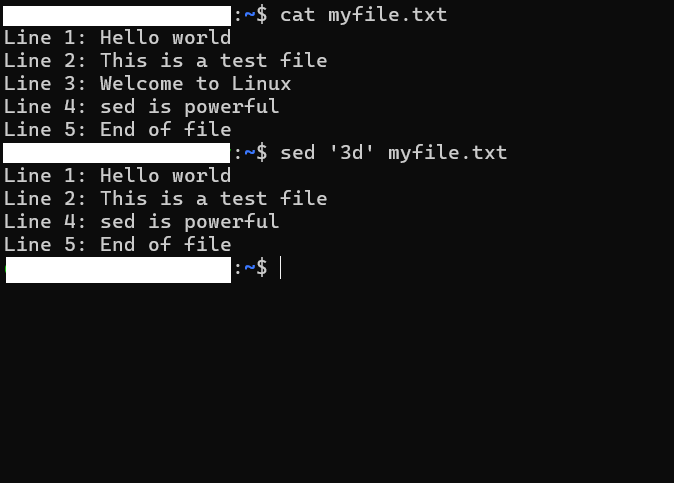
sed:切割日志的精确手术刀
日志文件太大时(比如 10GB),直接 grep 可能还是信息 overload。如果事故发生在特定时间窗口,sed 可以帮你切出那段日志,保存成小文件,便于分析或分享。
真实场景:导出事故时间窗口的日志
# 语法:sed -n '/开始时间/,/结束时间/p' 源文件 > 目标文件
# 注意:时间格式必须和日志里的格式完全一致
sed -n '/2025-12-19 14:00/,/2025-12-19 14:05/p' logs/application.log > error_segment.log
这样,你就得到了一个只有几 MB 的 error_segment.log,下载到本地或发给同事都超级方便。
额外提示:sed 还能用于替换(如 sed 's/ERROR/WARNING/g'),但在日志分析中,提取时间段是最常见应用。记得备份原文件!
awk:处理列数据的分析高手
awk 擅长列式数据处理,对于格式规范的日志(如 Nginx 访问日志),它能在服务器上直接生成报告,无需额外工具。
真实场景 A:遭到攻击,查找恶意 IP
服务 CPU 飙升,怀疑 CC 攻击或爬虫。我们分析 Nginx 日志,找出访问量最高的 IP(假设 IP 在第一列)。
# 1. awk '{print $1}':提取第一列(IP)
# 2. sort:排序,把相同的 IP 排在一起
# 3. uniq -c:去重并统计每个 IP 出现的次数
# 4. sort -nr:按次数(n)倒序(r)排列
# 5. head -n 10:取前 10 名
awk '{print $1}' access.log | sort | uniq -c | sort -nr | head -n 10
真实场景 B:找出响应最慢的接口
Nginx 日志中响应时间在最后一列,我们找出超过 1 秒的请求(假设 URL 在第 7 列)。
# $NF 代表最后一列
# 打印所有响应时间大于 1 秒的 URL
awk '$NF > 1.000 {print $7, $NF}' access.log
额外提示:awk 的脚本能力很强,可以自定义函数(如计算平均响应时间)。结合管道,它是日志统计的利器。
总结
以上例子都是我日常工作中亲测有效的,建议把这些命令刻在脑子里,或者直接收藏本文。下次遇到生产问题,对着场景复制粘贴,就能快速上手。熟练使用这些工具,不仅能提升排查效率,还能让你在团队中脱颖而出。记住,日志分析是后端开发的“内功”,多练多用,自然水到渠成。
评论区