


MySQL数据实时同步到Elasticsearch的高效解决方案:架构设计与技术选型深度解析
一、企业级数据同步的挑战与演进
在数字化时代,企业数据呈现爆炸式增长。某头部电商平台统计显示,其商品数据库日均增量达2TB,传统MySQL的查询响应时间从最初的200ms飙升至5s以上。这直接催生了Elasticsearch(ES)作为专业检索引擎的广泛应用。但数据同步面临三大核心挑战:
- 数据一致性:某金融系统曾因双写失败导致1.2亿交易记录丢失
- 实时性要求:直播电商场景要求库存变更在500ms内同步到搜索服务
- 系统扩展性:某社交平台日增10亿级动态数据,同步架构需支持动态扩容
二、六大同步方案技术全景图
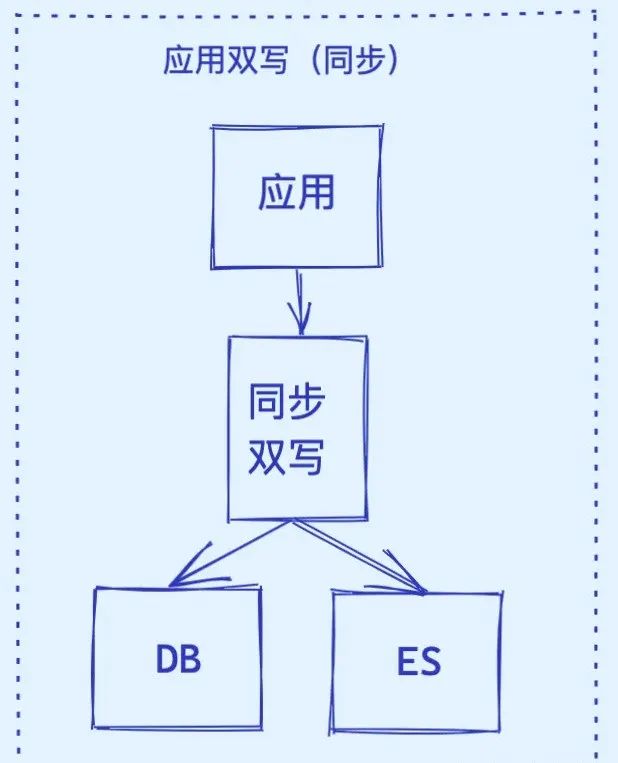
1. 同步双写:强一致性的代价
架构实现:
同步双写是一种数据同步策略,它指的是在主数据库(如MySQL)上进行数据修改操作时,同时将这些修改同步写入到ES中。这种策略旨在确保两个数据库之间的数据一致性,并优化系统的读写性能。
// Spring Boot伪代码示例
@Transactional
public Product createProduct(ProductDTO dto) {
// MySQL写入
Product product = productRepository.save(convertToEntity(dto));
// ES同步写入
try {
elasticsearchTemplate.save(convertToESDocument(product));
} catch (Exception e) {
// 补偿策略:重试队列+告警
retryQueue.push(product.getId());
throw new SyncException("ES写入失败");
}
return product;
}
实现方式
直接同步
在业务代码中,每次对MySQL数据库进行写入操作时,同时执行对ES的写入操作。这种方式简单直接,但可能增加代码的复杂性和出错的风险。
使用中间件
利用消息队列(如Kafka)、数据变更捕获工具(如Debezium)或ETL工具(如Logstash)等中间件来捕获MySQL的数据变更事件,并将这些事件转发到ES进行同步。这种方式可以解耦业务代码与数据同步逻辑,提高系统的可扩展性和可维护性。
触发器与存储过程
在MySQL中设置触发器或编写存储过程,在数据发生变更时自动触发ES的写入操作。这种方式可以减少业务代码的侵入性,但可能会增加MySQL的负担并影响性能。
关键优化:
- 二级重试机制:本地重试(3次/5s间隔)+ Dead Letter Queue
- 断路器模式:Hystrix熔断保护MySQL主业务
- 异步确认:通过Redis记录同步状态
典型事故:某票务系统双写超时引发数据库连接池耗尽,采用「先DB后ES+异步补偿」架构后,系统吞吐量提升4倍。
2. 异步双写:最终一致性的平衡艺术
异步双写在主数据库写入时,不等待备库(如 ES)确认即可完成写入操作。这种方式减少了写入延迟,提高系统性能。
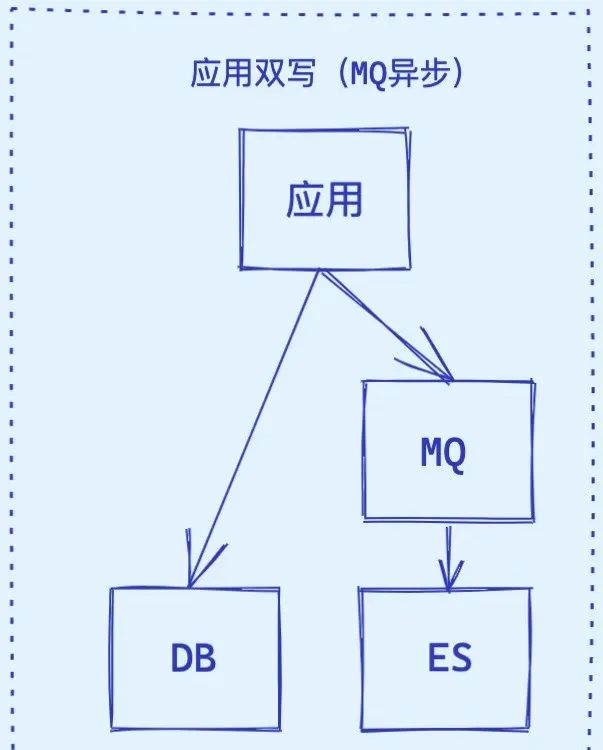
架构演进:
graph LR
A[业务服务] --> B[MySQL]
A --> C[Kafka Producer]
C --> D[Kafka Topic]
D --> E[ES Consumer]
E --> F[Elasticsearch]
性能对比(单节点测试):
| 方案 | QPS | 平均延迟 | 99分位延迟 |
|---|---|---|---|
| 同步双写 | 1200 | 85ms | 320ms |
| 异步双写 | 5800 | 22ms | 95ms |
消息积压处理:
- 动态分区扩展:基于Lag监控自动扩容Consumer
- 批量提交优化:调整
max.poll.records与fetch.min.bytes - 背压机制:Guava的RateLimiter控制处理速率
优缺点
- 优点:
- 提高系统可用性,备库问题不影响主库。
- 降低主库写入延迟,提升整体性能。
- 支持多数据源同步,便于扩展。
- 缺点:
- 硬编码问题:接入新数据源需要实现新的消费者代码。
- 系统复杂度增加:需要额外引入消息中间件。
- 实时性较低,数据一致性存在风险。
应用场景
3. Logstash同步:轻量级ETL方案
Logstash 是一个开源数据处理工具,能够从多个数据源采集数据,进行转换后发送至目标存储(如 Elasticsearch)。
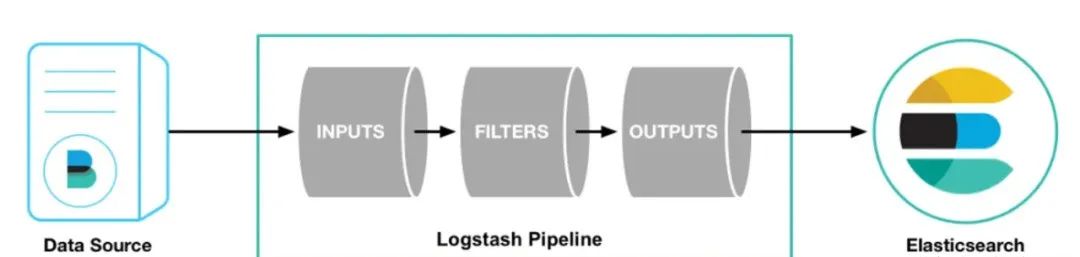
增量同步配置:
input {
jdbc {
jdbc_driver_library => "mysql-connector-java-8.0.28.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/mydb"
jdbc_user => "root"
schedule => "*/10 * * * * *"
statement => "SELECT * FROM products WHERE update_time > :sql_last_value"
use_column_value => true
tracking_column => "update_time"
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "products"
document_id => "%{id}"
}
}
性能瓶颈突破:
- 游标分页优化:使用
WHERE id > ? LIMIT 1000替代OFFSET - 多线程配置:
jdbc_default_page_size与workers参数调优 - 字段映射预定义:通过template.json预置mapping
优缺点
- 优点:
- 不改变原代码,减少硬编码。
- 无侵入性,系统性能不受影响。
- 缺点:
- 时效性较差,存在一定的同步延迟。
- 对数据库有轮询压力,需优化轮询策略。
- 无法同步删除操作,需手动删除 ES 数据。
4. Binlog实时同步:数据库底层协议的力量
Binlog 是 MySQL 中的二进制日志,记录了数据库的所有变更操作。使用 Binlog 实现实时同步,可以确保数据一致性并实时捕获变更。
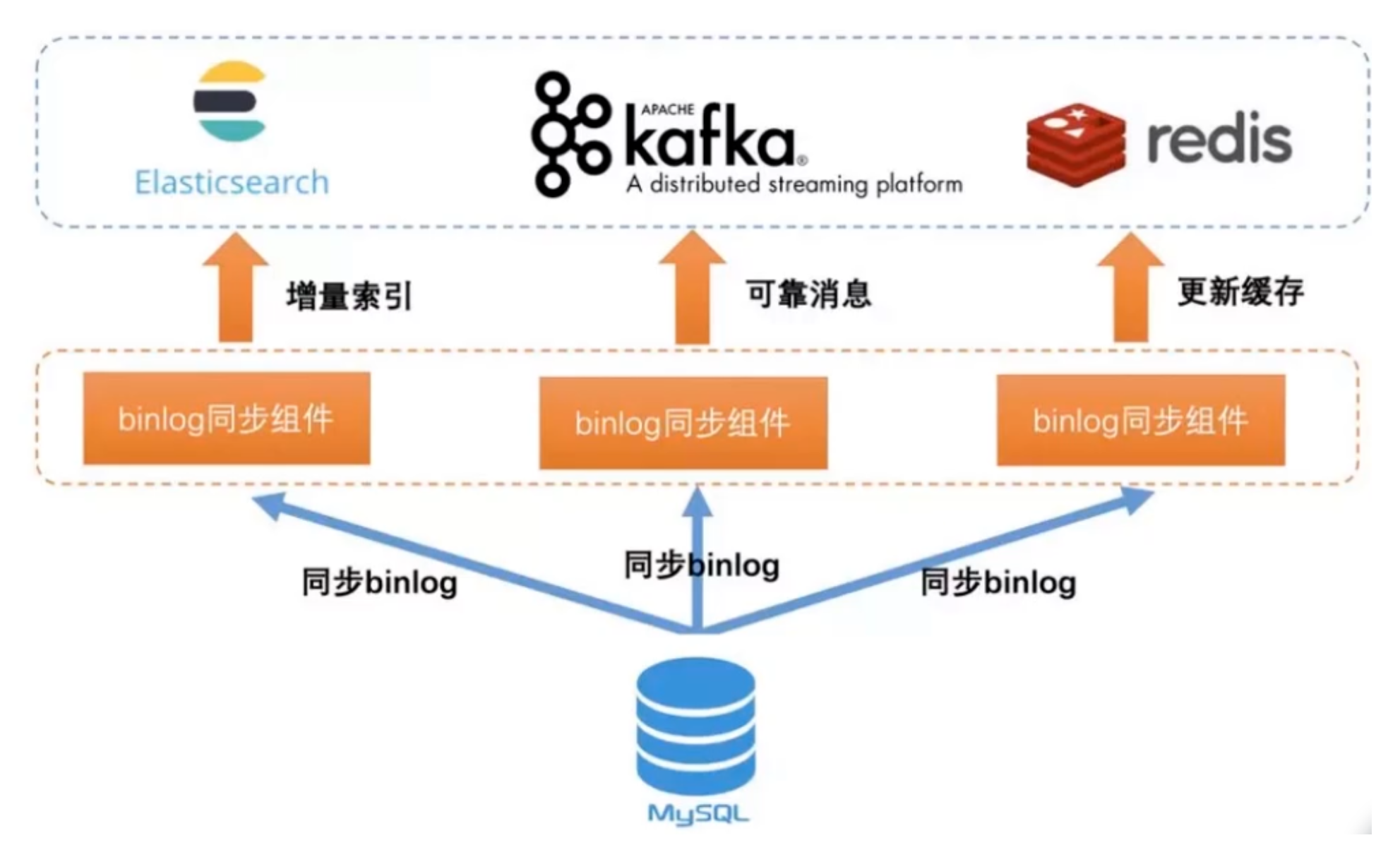
技术选型对比:
| 工具 | 开发语言 | 支持格式 | 数据过滤 | 监控管理 |
|---|---|---|---|---|
| Canal | Java | RAW/JSON | 支持 | 完善 |
| Maxwell | Ruby | JSON | 简单 | 基础 |
| Debezium | Java | Avro/JSON | 强大 | 企业级 |
高可用架构:
graph TD
A[MySQL Master] --> B[VIP]
B --> C[Canal Server 1]
B --> D[Canal Server 2]
C --> E[ZooKeeper]
D --> E
E --> F[Kafka Cluster]
同步延迟监控体系:
- Prometheus监控指标:
canal_instance_delay - 实时告警规则:延迟超过30s触发PagerDuty
- 延迟补偿策略:定时全量校验+差异修复
优缺点
- 优点:
- 高实时性,数据变更能迅速同步。
- 无侵入性,原系统无需更改。
- 缺点:
- 配置与维护工具较复杂。
- 高并发时,可能影响数据库性能。
5. Canal数据同步:阿里巴巴的最佳实践
Canal 是阿里巴巴提供的开源工具,模拟 MySQL 从库,实时捕获 Binlog 数据并同步到 Elasticsearch。
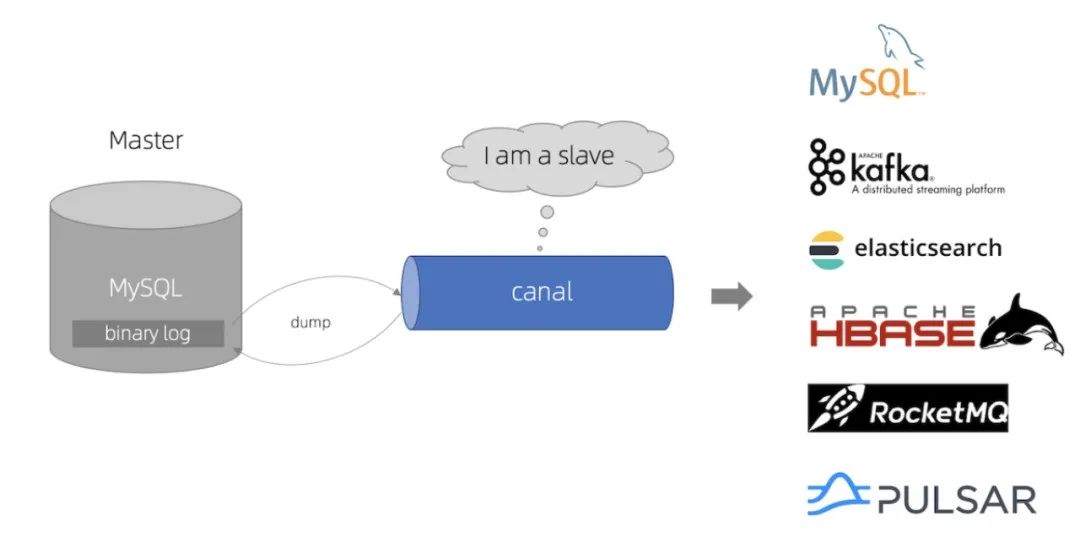
部署拓扑优化:
# 集群部署示例
docker run -p 11111:11111 --name canal-server \
-e canal.instance.mysql.slaveId=1234 \
-e canal.zkServers=zk1:2181,zk2:2181 \
canal/canal-server:v1.1.5
消息路由策略:
- 按表名路由到不同Kafka Topic
- 动态过滤系统表(如
sys_*) - DDL变更特殊处理通道
数据转换技巧:
// 自定义消息转换器
public class CustomMessageTransformer implements EntryHandler {
@Override
public void handleEntry(Entry entry) {
if (entry.getEntryType() == EntryType.ROWDATA) {
RowChange rowChange = RowChange.parseFrom(entry.getStoreValue());
for (RowData rowData : rowChange.getRowDatasList()) {
// 处理JSON字段转换
if (entry.getHeader().getTableName().equals("user")) {
transformJsonField(rowData.getAfterColumnsList());
}
}
}
}
}
优缺点
- 优点:
- 高实时性,低同步延迟。
- 无侵入性,数据同步透明。
- 缺点:
- 需要额外配置 Canal 服务和客户端。
6. 阿里云DTS:企业级全托管服务
阿里云 DTS 是一个实时数据传输服务,支持关系型和非关系型数据库之间的数据同步。它具备高可用性和动态适配功能,适合复杂的数据交互需求。
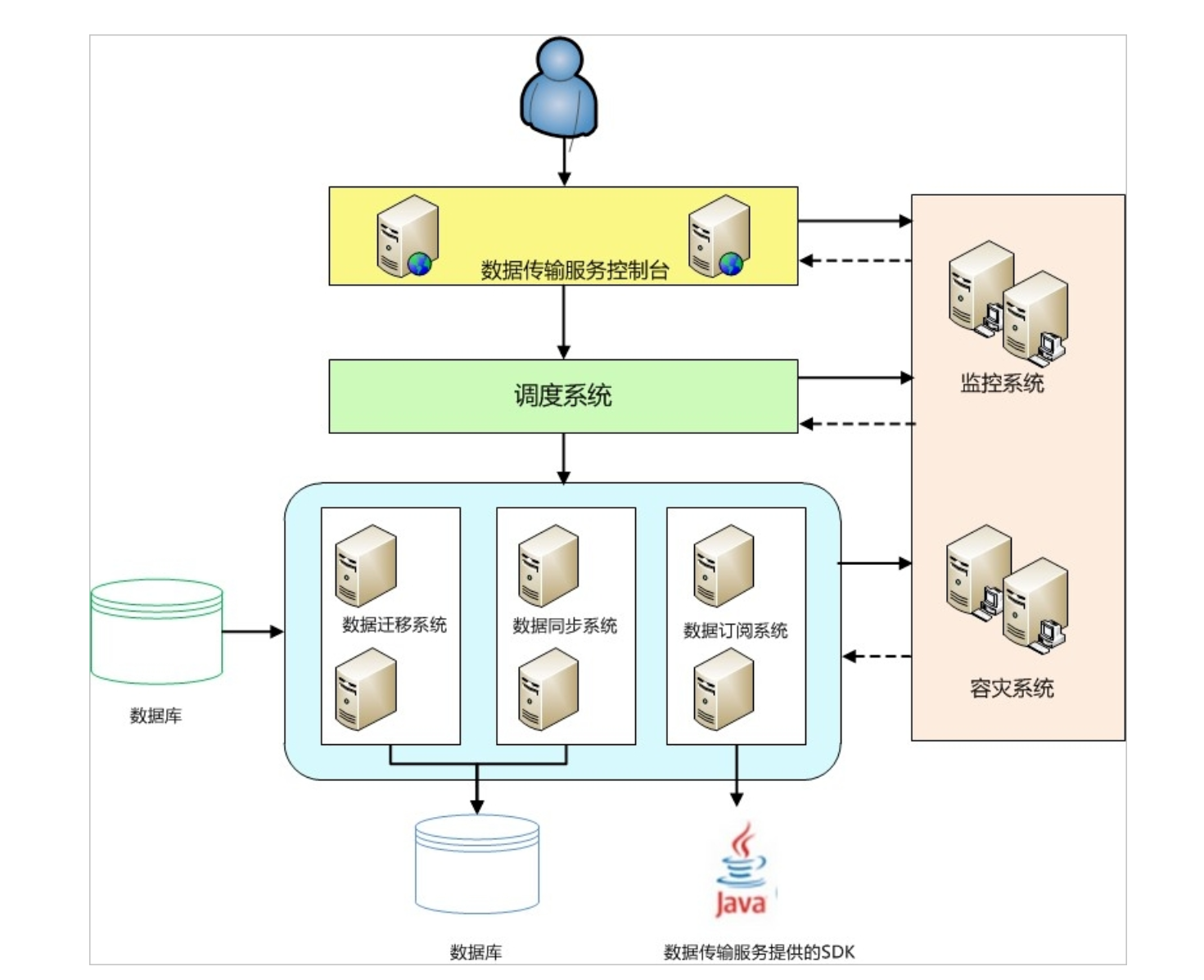
功能矩阵:
| 功能模块 | 说明 | SLA保障 |
|---|---|---|
| 数据迁移 | 异构数据库迁移 | 99.95%可用性 |
| 实时同步 | 毫秒级延迟 | <1秒延迟 |
| 数据订阅 | 多客户端消费 | 消息不丢失 |
| 数据校验 | CRC32校验+全量对比 | 99.999%准确 |
成本优化实践:
- 闲时降配:业务低谷期自动降低DU配置
- 流量压缩:启用ZSTD压缩算法(压缩率提升40%)
- 索引预建:同步前在ES中预建优化后的索引模板
特性
- 高可用性:模块主备架构,实时监控节点健康状况。
- 动态适配:自动适配数据源地址的变更。
三、架构选型决策树
graph TD
A[实时性要求] --> B{延迟容忍度}
B --> |<1s| C[Binlog/Canal]
B --> |1s-1m| D[异步双写]
B --> |>5m| E[Logstash]
F[数据规模] --> G{日增量}
G --> |<10GB| C
G --> |10GB-1TB| D
G --> |>1TB| H[阿里云DTS]
I[团队能力] --> J{运维能力}
J --> |强| C
J --> |中等| D
J --> |弱| H
四、未来演进方向
- Serverless架构:基于Flink的无服务器同步方案
- 智能路由:根据查询模式动态调整索引分片
- HTAP融合:TiDB+ES的混合事务/分析处理
- 边缘计算:在CDN节点实现近用户端同步
"最好的同步方案不是技术最先进的,而是与业务场景完美契合的。" —— 某独角兽企业CTO
通过深入剖析六大方案的技术细节与实战经验,架构师可根据业务特征选择最优解。建议从「数据一致性等级」「团队技术栈」「成本预算」三个维度建立评估矩阵,定期进行架构健康度检查,确保同步系统始终高效运行。
评论区